- 함수 Function
- 그룹 함수
- 단일행 함수
- <문자열과 관련된 함수>
- LENGTH(문자열) : 해당 전달된 문자열의 글자 수 반환
- LENGTHB(문자열) : 전달된 문자열의 바이트 수 반환
- INSTR : 문자열로부터 특정 문자의 위치값 반환
- SUBSTR : 문자열로부터 특정 문자열을 추출하는 함수
- LPAD / RPAD : 왼쪽 또는 오른쪽에 제시한 문자를 덧붙여서 최종 N길이만큼의 문자열을 반환
- LTRIM / RTRIM : 문자열의 왼쪽 또는 오른쪽에서 제거시키고자 하는 문자들을 찾아서 제거한 나머지 문자열을 반환
- <숫자와 관련된 함수>
- <날짜 관련 함수>
- MONTHS_BETWEEN
- ADD_MONTHS
- NEXT_DAY
- EXTRACT
- 언어설정 변경 방법
- <형변환 함수>
- TO_CHAR
- TO_DATE
- TO_NUMBER
- <NULL 처리 함수>
- NVL
- NVL2
- NULLIF
- <선택함수>
- DECODE
- CASE WHEN THEN
- <문자열과 관련된 함수>
<함수 Function>
⇒ 자바의 메서드 같은 존재 매개변수로 전달된 값들을 읽어서 계산한 결과를 반환 -> 호출해서 쓸 것
- 단일행 함수 : n개의 값을 읽어서 n개의 결과를 리턴(매 행마다 함수를 실행하고 결과값 반환)
- 그룹 함수 : n개의 값을 읽어서 그룹의 개수만큼 결과를 리턴(*하나의 그룹별로 함수 실행후 반환)
단일행 함수와 그룹함수는 함계 사용할 수 없다. : 결과행의 갯수가 다르기 때문
--------------------------------- <단일행 함수> ---------------------------------
<문자열과 관련된 함수>
▶ LENGTH / LENGTHB
- LENGTH(문자열) : 해당 전달된 문자열의 글자 수 반환
- LENGTHB(문자열) : 전달된 문자열의 바이트 수 반환
결과 값은 숫자로 반환 -> NUMBER
문자열 : 문자열 형식의 리터럴이나 문자열이 저장된 칼럼을 제시
SELECT LENGTH('오라클!'), LENGTHB('오라클!')
FROM DUAL;
DUAL : 가상테이블
: 산술연산이나 가상 칼럼등 값을 테스트 혹은 출력하기 위한 용도로 사용하는 테이블
▶ INSTR
- INSTR(문자열, 특정문자, 찾을 위치의 시작값, 순번) :
문자열로부터 특정 문자의 위치값 반환. 찾을 위치의 시작값, 순번은 생략 가능
찾을 위치의 시작값 : (1 / -1)
1 : 앞에서 부터 찾겠다(기본값)
-1 : 뒤에서부터 찾겠다.SELECT INSTR('AABAACAABBAA', 'B') FROM DUAL; -- 매개변수 생략시 기본값
SELECT INSTR('AABAACAABBAA', 'B', 1) FROM DUAL; -- (==) 매개변수 1이 기본값
-- 3 : 앞에서부터 첫번째에 위치하는 B의 위치값 AA"B"AACAABBAA
SELECT INSTR('AABAACAABBAA', 'B', -1) FROM DUAL;
-- 10 : 뒤에서부터 첫번째에 위치하는 B의 값을 앞에서부터 세서 반환 AABAACAAB"B"AA
SELECT INSTR('AABAACAABBAA', 'B', -1, 2) FROM DUAL;
-- 9 : B가 뒤에서부터 두번째에 위치하는 값을 앞에서부터 세서 반환 AABAACAA"B"BAA
SELECT INSTR('AABAACAABBAA', 'B', 1, 2) FROM DUAL;
-- 9 : B가 앞에서 두번째에 위치하는 값을 반환 AABAACAA"B"BAA
SELECT INSTR('AABAACAABBAA', 'B', -1, 0) FROM DUAL;
-- 범위를 벗어난 순번을 제시시 오류 발생함. 1부터 시작하기 떄문에 0번이 없음.
- - 인덱스처럼 글자의 위치를 찾는 것은 맞지만
-- 자바처럼 0부터 세는 것이 아니라 1부터 시작한다.
-- EMPLOYEE 테이블에서 이메일에서 @의 위치를 찾아보기
SELECT INSTR(EMAIL, '@' ) AS "@의 위치"
FROM EMPLOYEE;
▶ SUBSTR
- SUBSTR (문자열, 처음위치, 추출할 문자갯수)
⇒ 문자열로부터 특정 문자열을 추출하는 함수
⇒ 결과값은 CHARACTER 타입으로 반환(문자열)
추출한 문자 갯수는 생략 가능(생략시 문자열 끝까지 추출)
처음 위치는 음수로 제시 가능 : 뒤에서 부터 N번째 위치에서부터 문자를 추출한다는 뜻
SELECT SUBSTR('SHOWMETHEMONEY', 7 ) FROM DUAL;
-- SHOWME"THEMONEY" // 7번째부터 모두
SELECT SUBSTR('SHOWMETHEMONEY', 5, 2) FROM DUAL;
-- SHOW"ME"THEMONEY // 5번부터 2개
SELECT SUBSTR('SHOWMETHEMONEY', 1, 6 ) FROM DUAL;
-- "SHOWME"THEMONEY // 1번부터 6개
SELECT SUBSTR('SHOWMETHEMONEY', -8, 3 ) FROM DUAL;
-- SHOWME"THE"MONEY // 8번부터 뒤쪽으로 3개
- - 주민등록번호에서 성별 부분을 추출해서 남자/여자를 체크
SELECT EMP_NAME, SUBSTR(EMP_NO, 8, 1 ) AS 성별
FROM EMPLOYEE;
- - 각 사원의 이메일에서 ID부분만 추출해서 조회(사원이름, 이메일, 추출된ID)
SELECT EMP_NAME, EMAIL, SUBSTR(EMAIL, 1, INSTR(EMAIL, '@')-1 ) AS ID
FROM EMPLOYEE
▶ LPAD / RPAD
- LPAD/RPAD(문자열, 최종적으로 반환할 문자의 길이(byte단위), 덧붙이고자 하는 문자)
: 제시한 문자열에 덧붙이고자 하는 문자를 왼쪽 또는 오른쪽에 덧붙여서
최종 N길이 만큼의 문자열을 반환
결과값은 CHARACTER 타입으로 반환
덧붙이고자 하는 문자는 생략가능(기본값 ' ')
SELECT LPAD(EMAIL, 16), EMAIL
FROM EMPLOYEE;
-- 덧붙이고자 하는 문자 생략시 ' '기본값이 공백임을 알 수 있음
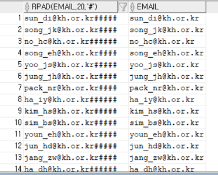
SELECT RPAD(EMAIL, 20, '#'), EMAIL
FROM EMPLOYEE;
-- 주민등록번호 조회 : 621205-1234567 => 621205-1******
-- 9번쨰부터 모두 *로 변경..
SELECT EMP_NAME, SUBSTR(EMP_NO, 1, 8)
FROM EMPLOYEE;
SELECT EMP_NAME, RPAD(SUBSTR(EMP_NO, 1, 8), 14, '*' ) AS 주민번호
FROM EMPLOYEE;

▶ LTRIM/RTRIM
- LTRIM/RTRIM(문자열, 제거시키고자 하는 문자)
: 문자열의 왼쪽 또는 오른쪽에서 제거시키고자 하는 문자들을 찾아서 제거한 나머지 문자열을 반환
SELECT LTRIM(' K H ') FROM DUAL;
-- "K H " // 기본값으로 왼쪽의 공백' '을 제거해준다
SELECT RTRIM(' K H ') FROM DUAL;
-- " K H" // 기본값으로 오른쪽의 공백' '을 제거해준다
SELECT LTRIM('123123KH123', '123') FROM DUAL;
-- 123123"KH123" // 맨앞의 123123이 제거
SELECT RTRIM('000012300456000', '0') FROM DUAL;
-- "000012300456"000 // 맨끝의 0만 제거
SELECT LTRIM('ACABACCKH', 'ABC') FROM DUAL;
-- ACABACC"KH"
-- 내가 제시하지 않은 문자를 만나기 전까지 제거해줌
-- 제거시키고자 하는 문자열을 통으로 제거하는 것이 아니라
-- 문자 하나하나가 다 존재하면 제거해주는 원리
▶ TRIM(BOTH/LEADING/TRAILING
- TRIM(BOTH/LEADING/TRAILING)
'제거하고자 하는 문자' FORM '문자열'
: 문자열의 양쪽/앞쪽/뒤쪽에 있는 특정 문자를 제거한 나머지 문자열을 반환
결과값은 CHARACTER 타입으로 반환
BOTH/LEADING/TRAILING : 생략가능, 생략시 기본값 BOTH
SELECT TRIM(' K H ') FROM DUAL;
-- "K H" 양쪽 공백 제거
SELECT TRIM('Z' FROM 'ZZZZKZZHZZ') FROM DUAL;
-- ZZZZ"KZZH"ZZ
- -SELECT TRIM('ZZZZKZZHZZ', 'Z') FROM DUAL;
-- 에러발생 / 매개변수 제시방법이 올바르지 않다
SELECT TRIM(BOTH 'Z' FROM 'ZZZZKZZHZZ') FROM DUAL;
-- ZZZZ"KZZH"ZZ // BOTH 가 기본값(앞, 뒤)
SELECT TRIM(LEADING 'Z' FROM 'ZZZZKZZHZZ') FROM DUAL;
-- ZZZZ"KZZHZZ" // 앞쪽만 제거됨
SELECT TRIM(TRAILING 'Z' FROM 'ZZZZKZZHZZ') FROM DUAL;
-- "ZZZZKZZH"ZZ // 뒤쪽만 제거됨
▶ LOWER/UPPER/INITCAP
- LOWER(문자열) : 문자열을 전부 소문자로 변경
- UPPER(문자열) : 문자열을 전부 대문자로 변경
- INITCAP(문자열) : 문자열에 들어가는 각 단어의 앞글자만 대문자로 변경
SELECT LOWER('Welcome to D class'), UPPER('Welcome to D class'), INITCAP('Welcome to D class')
FROM DUAL;
▶ CONCAT
- CONCAT(문자열1, 문자열2) : 전달된 문자열 두개를 하나의 문자열로 합쳐서 반환
SELECT CONCAT('가나다', '라마바사아')
FROM DUAL;
SELECT '가나다' || '라마바' || 1234
FROM DUAL;
-- SELECT CONCAT('가나다', 123, 'ABC')
-- FROM DUAL;
-- 에러발생 / 매개변수는 오직 두개의 문자열만 가능하다

▶ REPLACE
- REPLACE(문자열, 찾을문자, 바꿀문자) : 문자열로부터 찾을문자를 찾아서 바꿀문자로 바꾼 문자열을 반환
SELECT REPLACE('서울시 강남구 역삼동', '역삼동', '삼성동')
FROM DUAL;
-- 각 사원의 이메일 주소를 kh.or.kr에서 iei.or.kr로 변경된 문자열 출력하기
SELECT EMP_NAME, EMAIL, REPLACE(EMAIL, 'kh.or.kr', 'iei.or.kr')
FROM EMPLOYEE;
<숫자와 관련된 함수>
▶ ABS
- ABS(절대값을 구할 숫자) : 절대값을 구해주는 함수 (ABSOLUTE)
결과값은 NUMBER 형태로 반환SELECT ABS(-10) FROM DUAL;
SELECT ABS(-10.9) FROM DUAL;
▶ MOD
- MOD(숫자, 나눌값) : 두 수를 나눈 나머지값을 반환
SELECT MOD(10, 3) FROM DUAL;
SELECT MOD(-10, 3) FROM DUAL;
SELECT MOD(10.9, 3) FROM DUAL;
▶ ROUND
- ROUNG(반올림하고자하는수, 반올림위치) : 반올림처리해주는 함수
반올림위치 : 소숫점 기준으로 아래 N번째 수에서 반올림한다.(생략시 기본값은 0)
SELECT ROUND(123.456) FROM DUAL; -- 123
SELECT ROUND(123.456, 1) FROM DUAL; -- 123.5
SELECT ROUND(123.456, 2) FROM DUAL; -- 123.46
SELECT ROUND(123.456, -1) FROM DUAL; -- 120
SELECT ROUND(123.456, -2) FROM DUAL; -- 100
▶ CEIL
- CEIL(올림처리할 숫자) : 소숫점 아래의 수를 올림처리해주는 함수SELECT CEIL(123.456)
FROM DUAL;
▶ FLOOR
- FLOOR(버림처리하고자하는숫자) : 소숫점 아래의 수를 무조건 버림처리해주는 함수
날짜 계산할때 많이 사용됨SELECT FLOOR(123.999)
FROM DUAL; -- 123
-- 각 직원별로 근무일수 구하기(오늘날짜-고용일 = 소숫점)
SELECT EMP_NAME, SYSDATE-HIRE_DATE, FLOOR(SYSDATE-HIRE_DATE) || '일' AS 근무일수
FROM EMPLOYEE;
▶ TRUNC
- TRUNC(버림처리할숫자, 위치) : 위치 지정이 가능한 버림처리 함수
SELECT TRUNC(123.786) FROM DUAL; -- 위치값 생략시 기본값은 0
SELECT TRUNC(123.786, 1) FROM DUAL; -- 123.7
SELECT TRUNC(123.786, 2) FROM DUAL; -- 123.78
SELECT TRUNC(123.786, -1) FROM DUAL; -- 120
SELECT TRUNC(123.786, -2) FROM DUAL; -- 100
<날짜 관련 함수>
- Date타입 : 년도, 월, 일, 시, 분, 초를 다 포함한 자료형
SELECT SYSDATE FROM DUAL;
▶ MONTHS_BETWEEN(DATE1, DATE2)
- MONTHS_BETWEEN(DATE1, DATE2)
: 두 날짜사이의 개월수 반환(결과값은 NUMBER)
-- DATE2가 더 미래일 경우 음수가 나옴.
-- 각 직원별 근무일수, 근무개월수 조회
SELECT EMP_NAME,
FLOOR(SYSDATE-HIRE_DATE) || '일' 근무일수,
FLOOR(ABS(MONTHS_BETWEEN(HIRE_DATE, SYSDATE ))) || '개월' 근무개월수
FROM EMPLOYEE;
▶ ADD_MONTHS(DATE, NUMBER)
- ADD_MONTHS(DATE, NUMBER)
: 특정 날짜에 해당 숫자만큼 개월수를 더한 날짜를 반환(결과값은 DATE타입)
-- 오늘날짜에서 5개월 이후 조회
-- 전체 사원들의 1년 근속일(==입사일 기준 1주년)
SELECT EMP_NAME, HIRE_DATE
FROM EMPLOYEE;
▶ NEXT_DAY(DATE, 요일(문자/숫자))
- NEXT_DAY(DATE, 요일(문자/숫자))
: 날짜에서 가장 가까운 요일을 찾아 그 날짜를 반환(결과값은 DATE)
-- 1:일요일, 2:월요일, 3:화요일 ... 7:토요일
▶ EXTRACT : 년도 또는 월 또는 일 정보를 추출해서 NUMBER자료형으로 반환
- EXTRACT
: 년도 또는 월 또는 일 정보를 추출해서 NUMBER자료형으로 반환
- EXTRACT(YEAR FROM 날짜) : 특정 날짜로부터 년도만 추출
- EXTRACT(MONTH FROM 날짜) : 특정 날짜로부터 월만 추출
- EXTRACT(DAT FROM 날짜) : 특정 날짜로부터 일만 추출
SELECT EXTRACT(YEAR FROM SYSDATE),
EXTRACT(MONTH FROM SYSDATE),
EXTRACT(DAY FROM SYSDATE)
FROM DUAL;
※ 언어설정 변경 방법 ※
-- DDL(데이터 정의 언어) : CREATE, ALTER, DROP
ALTER SESSION SET NLS_LANGUAGE = AMERICAN;
<형변환 함수>
▶ TO_CHAR
- TO_CHAR(NUMBER/DATE, 포맷)
⇒ NUMBER/DATE => CHARACTER
1. 숫자를 문자열로
SELECT TO_CHAR(1234)
FROM DUAL; -- 1234 -> '1234'
SELECT TO_CHAR(1234,'00000000')
FROM DUAL; -- 1234 -> '00001234' 빈칸이 있다면 0으로 채움
SELECT TO_CHAR(1234, '99999')
FROM DUAL; -- 1234 -> ' 1234' 빈칸을 ' '로 채움
SELECT TO_CHAR(1234, 'L00000')
FROM DUAL; -- 1234 -> '₩01234' L:LOCAL => 현재 설정된 나라의 화폐단위 표시
SELECT TO_CHAR(1234, 'L99,000')
FROM DUAL; -- 1234 -> '₩1,234'
-- 급여정보를 3자리마다 ','로 끊어서 확인하기
SELECT EMP_NAME, TO_CHAR(SALARY, '999,999,999') AS 급여
FROM EMPLOYEE; -- ' 8,000,000'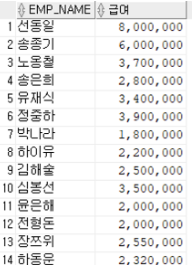
2. 날짜를 문자열로
SELECT SYSDATE
FROM DUAL;
SELECT TO_CHAR(SYSDATE)
FROM DUAL;
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD')
FROM DUAL;
-- 아래 내용을 위와 같이 간결하게 기술이 가능하다.
/*
SELECT EXTRACT(YEAR FROM SYSDATE) || '-'
|| EXTRACT(MONTH FROM SYSDATE) "YYYY-MM"
FROM DUAL;
*/
SELECT SYSDATE
FROM DUAL;
SELECT TO_CHAR(SYSDATE)
FROM DUAL;
- 시 분 초 : 오전(AM)/오후(PM)
-- EX) 오전 00:00:00
SELECT TO_CHAR(SYSDATE, 'AM HH:MI:SS')
FROM DUAL;
SELECT TO_CHAR(SYSDATE, 'HH24:MI:SS')
FROM DUAL;
SELECT TO_CHAR(SYSDATE, 'MON DY, YYYY')
FROM DUAL;
-- MON : 'X월'
-- DY : 월, 화, 수, … 요일을 알려주되 몇일인지 알려주지 않음
-- DAY : 월요일, 화요일, 수요일, ..
SELECT TO_CHAR(SYSDATE, 'DAY')
SELECT TO_CHAR(SYSDATE, 'DY')
FROM DUAL;
1) 년도로써 쓸 수 있는 포맷
SELECT TO_CHAR(SYSDATE, 'YYYY'),
TO_CHAR(SYSDATE, 'RRRR'),
TO_CHAR(SYSDATE, 'YY'),
TO_CHAR(SYSDATE, 'RR'),
TO_CHAR(SYSDATE, 'YEAR')
FROM DUAL;
YY와 RR의 차이점
-- R : ROUND의 약자
-- RR : 50년 기준으로 작으면 20, 크면 19 -> 89:2089 / 49:1949
-- YY : 년도의 앞 두자리에 무조건 20이 붙음 -> 89:2089 / 49:2049
2) 월로써 쓸 수 있는 포맷
SELECT TO_CHAR(SYSDATE, 'MM'),
TO_CHAR(SYSDATE, 'MON'),
TO_CHAR(SYSDATE, 'MONTH'),
TO_CHAR(SYSDATE, 'RM')
FROM DUAL;
-- RM : 로마숫자로 반환
3) 일로써 쓸 수 있는 포맷
SELECT TO_CHAR(SYSDATE, 'D'),
TO_CHAR(SYSDATE, 'DD'),
TO_CHAR(SYSDATE, 'DDD')
FROM DUAL;
-- D : 일주일 기준으로 일요일부터 오늘이 며칠째인지 알려주는 포맷
-- 일:1, 월:2, 화:3 ...
-- DD : 1달 기준으로 1일부터 며칠째인지 알려주는 포맷
-- DDD : 1년 기준으로 1월 1일부터 며칠째인지 알려주는 포맷
4) 요일로써 쓸 수 있는 포맷
SELECT TO_CHAR(SYSDATE, 'DY'),
TO_CHAR(SYSDATE, 'DAY')
FROM DUAL;
-- 2023년 11월 24일 (금) 포맷으로 적용시키기
SELECT TO_CHAR(SYSDATE, 'YYYY"년" MM"월" DD"일" (DY)')
FROM DUAL;
-- 사원명, 입사일(위의 포맷을 적용)
-- 2010년 이후에 입사한 사원들만 구하기
SELECT EMP_NAME, TO_CHAR(HIRE_DATE, 'YYYY"년" MM"월" DD"일" (DY) ')
FROM EMPLOYEE
--WHERE EXTRACT(YEAR FROM HIRE_DATE) >= 2010;
WHERE HIRE_DATE >= '10/01/01'; -- 자동형변환
▶ TO_DATE
- TO_DATE (NUMBER/CHARACTER, 포맷)
⇒ NUMBER/CHARCATER => DATE
SELECT TO_DATE(20231124)
/*(==) TO_DATE('20231124') */
FROM DUAL;
-- 기본포맷 YY/MM/DD로 변환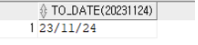
-- 20000101을 NUMBER값에서 DATE자료형으로 변환하고자 한다면?
SELECT TO_DATE(000101) -- 000101 => 101 : NUMBER자료형에서 앞이 0으로 시작하면 전부다 삭제된다.
FROM DUAL; -- 101이라 DATE 형식이 아니라 에러발생
SELECT TO_DATE('000101') -- 000101 => 00/01/01 : 0으로시작하는 년도는 반드시 ''문자열로 다뤄야 함
FROM DUAL;
SELECT TO_DATE(20000101) -- 00/01/01
FROM DUAL;
SELECT TO_DATE('231124 183000', 'YYMMDD HH24MISS').
FROM DUAL;
SELECT TO_DATE('980630', 'YYMMDD')
FROM DUAL; -- 2098년도
-- TO_DATE() 를 이용해서 DATE형식으로 변환시
-- 두자리 년도에 대해 YY포맷을 적용시킬 경우 무조건 앞자리에 20년도가 추가된다
SELECT TO_DATE('980630', 'RRMMDD')
FROM DUAL; -- 2098년도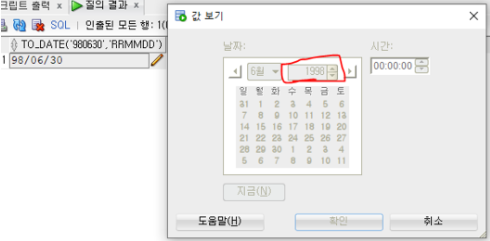
- 두자리 년도에 대해 RR포맷을 적용시킬 경우
-- 50이상이면 이전(19)
-- 50미만이면 현재세기(20)을 추가함
▶ TO_NUMBER
- TO_NUMBER(CHARACTER, 포맷)
⇒ CHARACTER => NUMBERSELECT '123'+'456'
FROM DUAL;
-- 579 : 자동형변환 이후 산술연산 수행
SELECT '10,000,000'+'550,000'
FROM DUAL;
-- 에러발행. 문자(,)가 포함되어 있기 때문에 자동형변환이 안됨
SELECT TO_NUMBER('10,000,000', '99,999,999')+TO_NUMBER('550,000', '999,999')
FROM DUAL;
SELECT TO_NUMBER('0123')
FROM DUAL;
-- NUMBER 자료형의 경우
<NULL 처리 함수>
- NVL(칼럼명, 해당칼럼값이 NULL일 경우 반환할 반환값)
- NVL2(칼럼명, 결과값1, 결과값2)
- NULLIF(비교대상1, 비교대상2) : 동등비교
- NVL(칼럼명, 해당칼럼값이 NULL일 경우 반환할 반환값)
- 해당 칼럼값이 존재할 경우(NULL이 아닐 경우) 기존의 칼럼값을 반환
- 해당 칼럼값이 존재하지 않을 경우(NULL일 경우) 내가 제시한 특정값을 반환-- 사원명, 보너스, 보너스가 없는 경우 0으로 출력
SELECT EMP_NAME, BONUS, NVL(BONUS, 0)
FROM EMPLOYEE;
-- 보너스가 포함된 연봉
-- NVL 처리 함수 없이..
SELECT EMP_NAME, (SALARY + SALARY * BONUS)*12 AS "보너스포함 연봉"
FROM EMPLOYEE;
-- NVL 처리 함수
SELECT EMP_NAME, (SALARY + (SALARY * NVL(BONUS, 0)))*12 AS "보너스포함 연봉"
FROM EMPLOYEE;
- NVL2(칼럼명, 결과값1, 결과값2)
-- 칼럼값이 NULL일 경우 : 결과값2 반환
-- 칼럼값이 NULL이 아닐 경우 : 결과값 1 반환-- 사원들 중에 보너스가 있는 사원은 "보너스가 있음" , 없는 사원은 "보너스가 없음" 반환
SELECT EMP_NAME, BONUS, NVL2(BONUS, '보너스 있음', '보너스 없음') AS 보너스유무
FROM EMPLOYEE;
- NULLIF(비교대상1, 비교대상2) : 동등비교
-- 두 값이 동일할 경우 : NULL 반환
-- 두 값이 다를 경우 : 비교대상1을반환
SELECT NULLIF(123,123)
FROM DUAL;
SELECT NULLIF(123,456)
FROM DUAL;
<선택함수>
▶ DECODE
-- 선택함수 : DECODE -> SWITCH문
-- 선택함수 친구 : CASE WHEN THEN 구문 -> IF문
<선택함수>
- DECODE(비교대상, 조건값1, 결과값1, 조건값2, 결과값2, 조건값3, 결과값3, ...,조건값N, 결과값N, 결과값)
자바의 SWITCH문과 유사함
비교대상에는 칼럼, 산술연산, 함수가 들어갈 수 있다.
-- 사번, 사원명, 주민번호, 주민등록번호로부터 성별을 추출해서 1이면 남자, 2면 여자
SELECT EMP_ID, EMP_NAME, EMP_NO
FROM EMPLOYEE;
SELECT EMP_ID, EMP_NAME, EMP_NO, DECODE(SUBSTR(EMP_NO, 8, 1), 1, '남자', 2, '여자', '없음' )
FROM EMPLOYEE;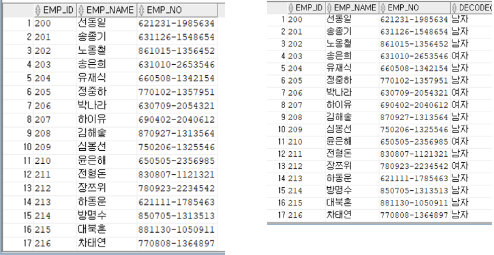
-- 직원들의 급여를 인상시켜서 조회
-- 직급코드가 'J7'인 사원은 급여를 10%인상
-- 직급코드가 'J6'인 사원은 급여를 15%인상
-- 직급코드가 'J5'인 사원은 급여를 20%인상
-- 그 외 직급코드인 사원은 급여를 5%인상
-- 사원명, 직급코드, 변경전 급여, 변경후 급여 조회.
SELECT EMP_NAME, JOB_CODE, SALARY,
DECODE(JOB_CODE, 'J7', SALARY*1.1, 'J6', SALARY*1.15,
'J5', SALARY*1.2, SALARY*1.05) AS"변경 후 급여"
FROM EMPLOYEE;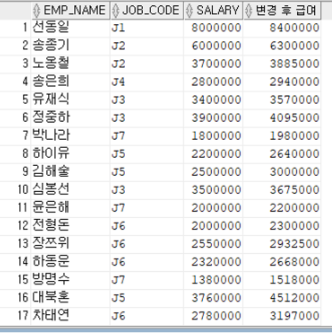
▶ CASE WHEN THEN 구문
- DECODE 선택함수와 비교한다면 DECODE는 해당 조건검사시 동등비교만을 수행
CASE WHEN THEN 구문의 경우 특정 조건을 내 마음대로 제시 가능
[표현법]
CASE WHEN 조건식1 THEN 결과값1
WHEN 조건식2 THEN 결과값2
WHEN 조건식N THEN 결과값N
ELSE 결과값
END
-- 자바의 if~else if문과 유사함
-- 사번, 사원명, 주민번호, 성별자리수에 따라 남자, 여자 구분
SELECT EMP_ID, EMP_NAME, EMP_NO,
CASE WHEN SUBSTR(EMP_NO, 8, 1) IN(1,3) THEN '남자'
ELSE '여자'
END 성별
FROM EMPLOYEE;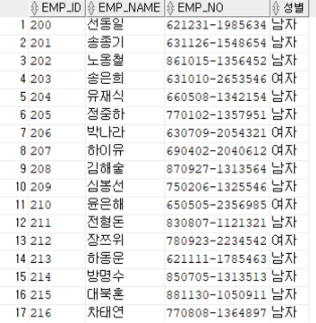
-- 위의 DECODE를 CASE WHEN THEN으로 변경해보기
SELECT EMP_NAME, JOB_CODE, SALARY,
CASE WHEN JOB_CODE = 'J7' THEN (SALARY*1.1)
WHEN JOB_CODE = 'J6' THEN (SALARY*1.15)
WHEN JOB_CODE = 'J5' THEN (SALARY*1.2)
ELSE (SALARY*1.05)
END 인상후급여
FROM EMPLOYEE;-- 위와 동일한 내용
SELECT EMP_NAME, JOB_CODE, SALARY,
CASE JOB_CODE WHEN 'J7' THEN (SALARY*1.1)
WHEN 'J6' THEN (SALARY*1.15)
WHEN 'J5' THEN (SALARY*1.2)
ELSE (SALARY*1.05)
END 인상후급여
FROM EMPLOYEE;
-- 사원명, 급여, 급여등급(SAL_LEVEL칼럼 사용X)
-- SALARY값이 500만원 초과일 경우 '고급'
-- 500만원 이하 350만원 초과일 경우 '중급'
-- 350만원 이하일 경우 '초급'
-- 급여등급
-- CASE WHEN THEN 구문으로 작성해보기
SELECT EMP_NAME, SALARY,
CASE WHEN SALARY > '5000000' THEN '고급'
WHEN SALARY > '3500000' THEN '중급'
ELSE '초급'
END 급여등급
FROM EMPLOYEE;